从零开始,一步一步学习caffe的使用,期间贯穿深度学习和调参的相关知识!Dropout 参数设置

Dropout是一个防止过拟合的层,只需要设置一个dropout_ratio就可以了。1
2
3
4
5
6
7
8
9
10
layer {
name: "drop7"
type: "Dropout"
bottom: "fc7-conv"
top: "fc7-conv"
dropout_param {
dropout_ratio: 0.5
}
}
Dropout 实现代码
1 |
|
Dropout 意义
Dropout可以被认为是集成大量深层神经网络的实用Bagging方法。但是Bagging方法涉及训练多个模型,并且在每个测试样本上评估多个模型。当每个模型都是一个大型神经网络时,Bagging方法会耗费很多的时间和内存。而Dropout则提供了一种廉价的Bagging集成近似,能够训练和评估指数级数量的神经网络。
- Dropout训练的集成包括所有从基础网络中除去神经元(非输出单元)后形成的子网络。只需将一些单元的输出乘零就能有效的删除一个单元(称之为乘零的简单Dropout算法)。假如基本网络有$n$个非输出神经元,则一共有$2^n$个子网络。
- Dropout的目标是在指数级数量的神经网络上近似Bagging过程。具体来说,在训练中使用Dropout时,我们会使用基于小批量产生较小步长的学习算法,如随机梯度下降。
- 每次在小批量中加载一个样本,然后随机抽样(用于网络中所有输入和隐藏单元的)不同二值掩码。
- 对于每个单元,掩码是独立采样的。通常输入单元被包括的概率为$0.8$,隐藏单元被包括的概率为$0.5$。
- 然后与之前一样,运行前向传播、反向传播和学习更新。
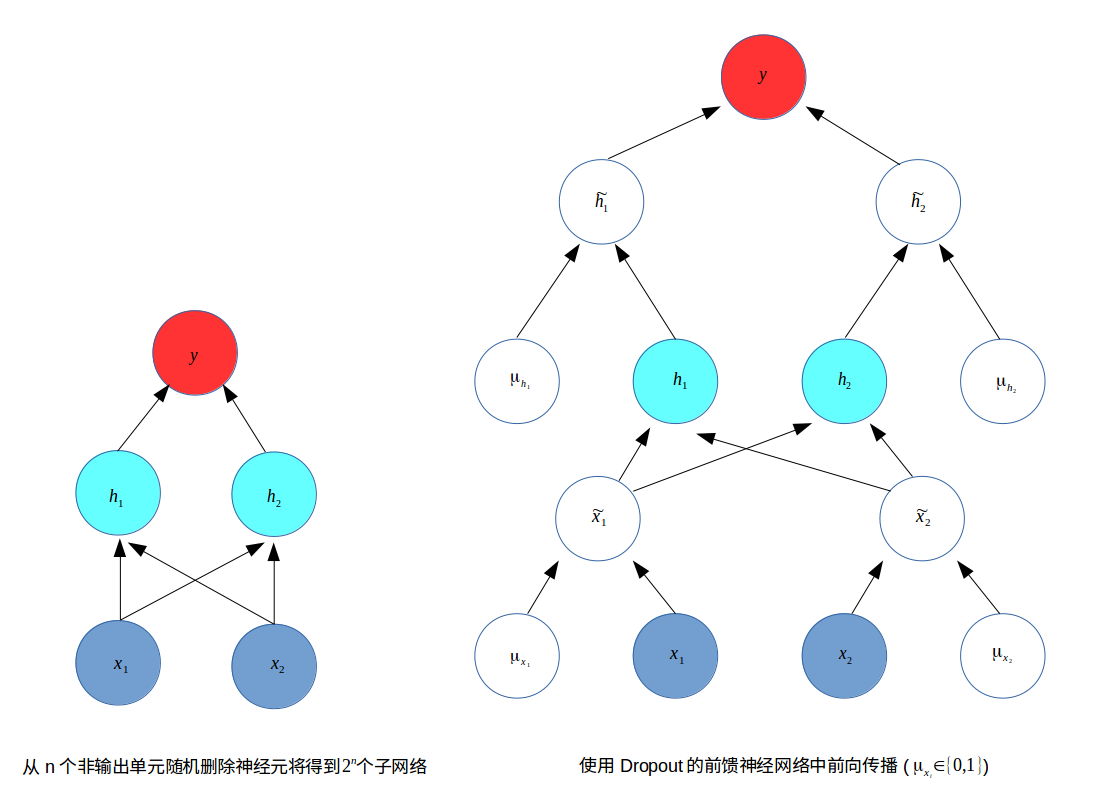
Dropout 小结
- Dropout优点
- 计算方便。训练过程中使用Dropout产生$n$个随机二进制数与状态相乘即可。每个样本每次更新的时间复杂度:$O(n)$,空间复杂度:$O(n)$。
- 适用广。Dropout不怎么限制适用的模型或训练过程,几乎在所有使用分布式表示且可以用随机梯度下降训练的模型上都表现很好。包括:前馈神经网络、概率模型、受限波尔兹曼机、循环神经网络等。
- 相比其他正则化方法(如权重衰减、过滤器约束和稀疏激活)更有效。也可与其他形式的正则化合并,得到进一步提升。
- Dropout缺点
- 不适合宽度太窄的网络。否则大部分网络没有输入到输出的路径。
- 不适合训练数据太小(如小于5000)的网络。训练数据太小时,Dropout没有其他方法表现好。
- 不适合非常大的数据集。数据集大的时候正则化效果有限(大数据集本身的泛化误差就很小),使用Dropout的代价可能超过正则化的好处。
- Dropout衍生方法
- Dropout作用于线性回归时,相当于每个输入特征具有不同权重衰减系数的$L^2$权重衰减,系数大小由其方差决定。但对深度模型而言,二者是不等同的。
- 快速Dropout (Wang and Manning,2013):利用近似解的方法,减小梯度计算中的随机性析解,获得更快的收敛速度。
- DropConnect (Wan,2013):将一个标量权重和单个隐藏单元状态之间的每个乘积作为可以丢弃的一个单元。
- $\mu$不取二值,而是服从正态分布,即$\mu\sim\mathcal{N}(1,I)$(Srivastava,2014)。
参考
Deep Learning Book
深度学习中的正则化